
# 数字人介绍
量子AI智能体,用于执行一些和 AI 相关的策略,分为三层。
- 感知层(Perception Layer)
- 处理层(Processing Layer)
- 执行层(Action Layer)
它支持语言控制,并且和各类通用服务的接口进行绑定,可以根据规则动态执行一系列命令,可以作为语音控制服务的中枢功能。
量子AI智能体并不是一个简单的“虚拟形象”,而是依靠大模型技术提供全方位的智能支持,从输入到输出,每一步都由大模型赋能,带来自然流畅的交互体验。
# 应用场景

# 流程概要
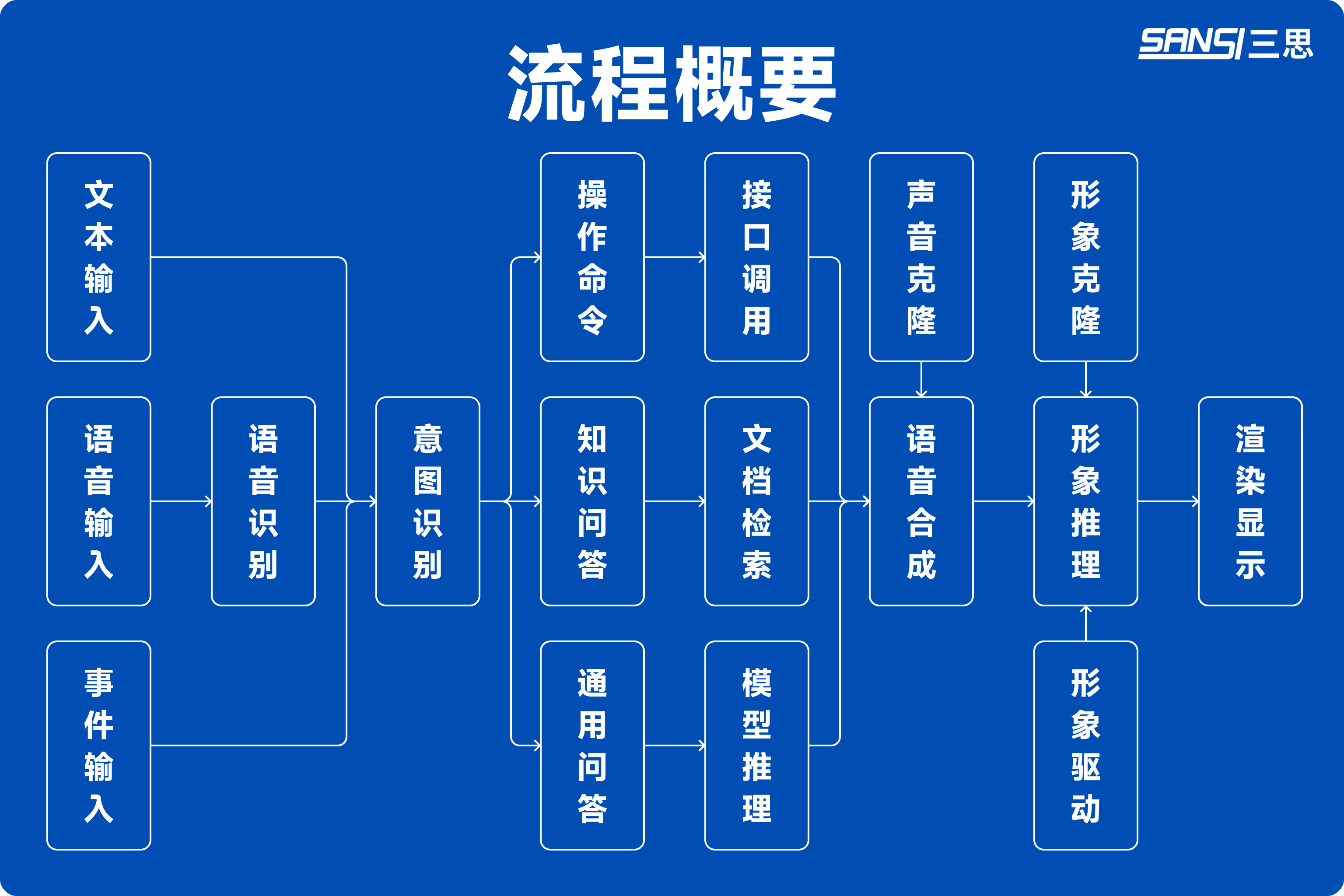
# 1. 语音识别 —— 听懂用户的语言
用户通过语音说出的内容,会由语音识别大模型实时转化为文字。
- 支持多语言识别
- 保证对话准确、高效
# 2. 意图识别 —— 思考与决策的核心
数字人的“大脑”由通用大模型驱动。它能够:
- 理解用户的提问、意图和上下文。
# 3. 模型推理 —— 从理解到生成的桥梁
通过对上下文语义、历史对话内容以及知识库信息的综合分析,大模型能够做出符合逻辑的判断与决策。
- 结合企业私有知识库、网上公开的知识库,给出准确、专业的答案。
- 根据不同业务需求(如执行命令、生成报告、控制设备),模型会将思考结果以结构化方式输出,供后续模块调用。
# 4. 语音合成 —— 赋予声音温度
当大模型生成回答后,系统会通过语音合成模型把文字转化为语音,并匹配特定音色。
- 可以选择男声、女声、不同语气风格
- 保证声音自然、富有情感,接近真人交流
# 5. 形象驱动 —— 让声音与形象同步
数字人的嘴型会与合成语音保持同步,由大模型完成口型推理。
- 精准对齐音节与口型
- 确保“所说即所见”,提升沉浸感
# 6. 渲染显示 —— 栩栩如生的表现力
最后,数字人形象通过大模型驱动的推理与渲染技术展现出来。
- 面部表情、肢体动作与语境匹配
- 支持多场景、多风格形象展示
- 带来更贴近真实的交互体验
# 总结
数字人全流程由大模型驱动:
听懂 → 理解 → 思考 → 表达 → 表演
不仅仅是一个虚拟界面,而是一个能听、能说、能思考、能互动的智能伙伴,为企业和用户打造更自然、更高效的交互体验。
部署手册 →